Abstract
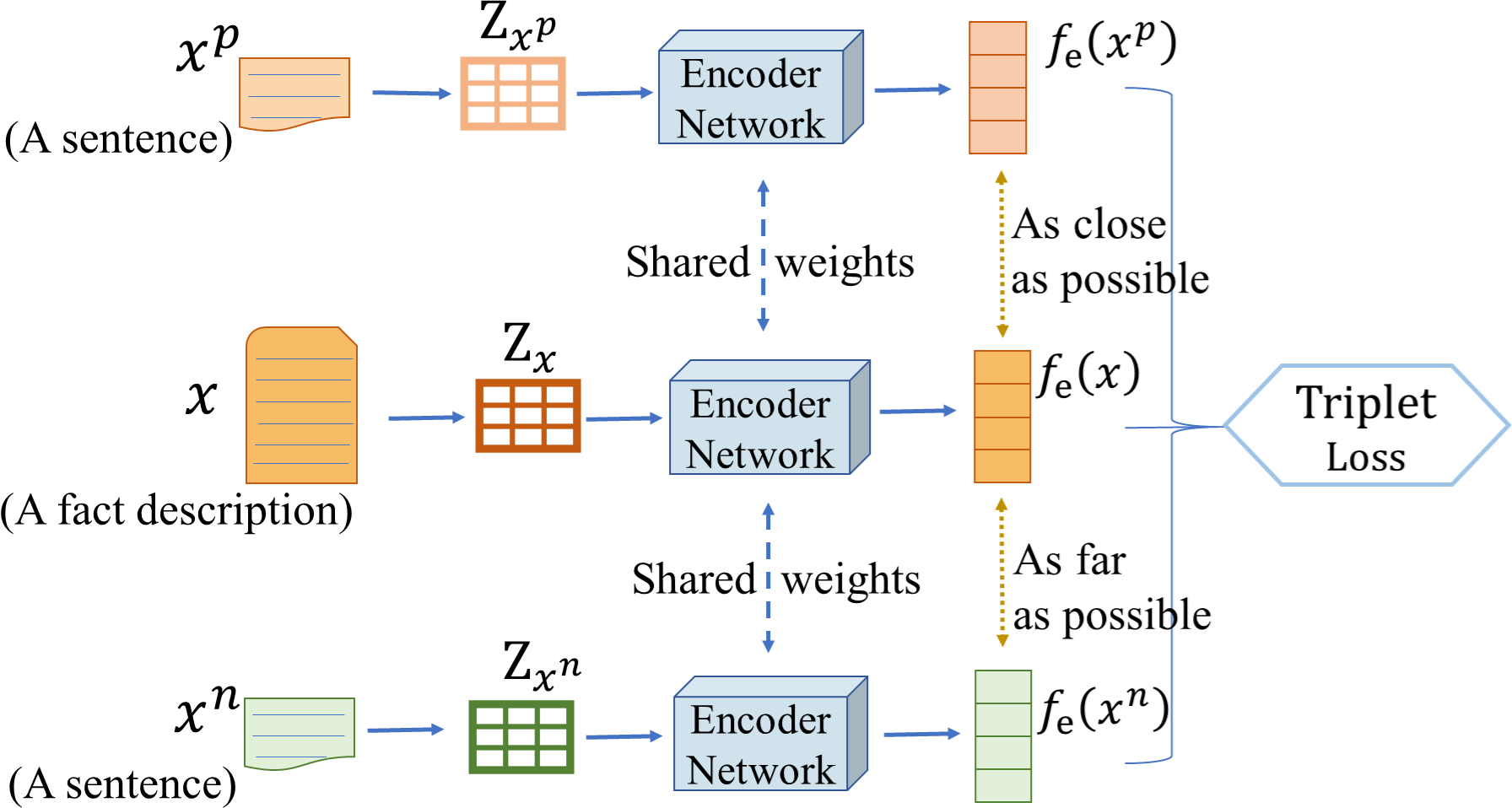
Recently, a rising number of works has been focusing on tasks in the legal field for providing references to professionals in order to improve their work efficiency. Learning legal text representations, being the most common initial step, can strongly influence the performance of downstream tasks. Existing works have shown that utilizing domain knowledge, such as legal elements, in text representation learning can improve the prediction performance of downstream models. However, existing methods are typically focused on specific downstream tasks, hindering their effective generalization to other legal tasks. Moreover, these models tend to entangle various legal elements into a unified representation, overlooking the nuances among distinct legal elements. To solve the aforementioned limitation, we (1) introduce a generic model, called eVec (legal text to element-related Vector), based on a triplet loss to learn discriminative representations of legal texts concerning a specific element, and (2) present a framework eVecs for learning disentangled representations w.r.t. multiple elements. The learned representations are independent of each other in terms of elements, and can be directly applied to or fine-tuned for various downstream tasks. We conducted comprehensive experiments on two real-world legal applications, the results of which indicate that the proposed model outperforms a range of baselines by a margin of up to 34.2% on a similar case matching task and 14% on a legal element identification task. When a small quantity of labeled data is accessible, the proposed model’s superior performance becomes even more evident.